In late 2023, the Meta OSS (Open Source Software) Team requested all Meta teams to move the CI deployments from CircleCI to Github Actions. Voltron Data and Meta in collaboration migrated all the deployed Velox CI jobs. For the year 2024, Velox CI spend was on track to overshoot the allocated resources by a considerable amount of money. As part of this migration effort, the CI workloads were consolidated and optimized by Q2 2024, bringing down the projected 2024 CI spend by 51%.
Continuous Integration (CI) is crucial for Velox’s success as an open source project as it helps protect from bugs and errors, reduces likelihood of conflicts and leads to increased community trust in the project. This is to ensure the Velox builds works well on a myriad of system architectures, operating systems and compilers - along with the ones used internally at Meta. The OSS build version of Velox also supports additional features that aren't used internally in Meta (for example, support for Cloud blob stores, etc.).
When a pull request is submitted to Velox, the following jobs are executed:
Linting and Formatting workflows:
Header checks
License checks
Basic Linters
Ensure Velox builds on various platforms
MacOS (Intel, M1)
Linux (Ubuntu/Centos)
Ensure Velox builds under its various configurations
Debug / Release builds
Build default Velox build
Build Velox with support for Parquet, Arrow and External Adapters (S3/HDFS/GCS etc.)
PyVelox builds
Run prerequisite tests
Unit Tests
Benchmarking Tests
Conbench is used to store and compare results, and also alert users on regressions
Various Fuzzer Tests (Expression / Aggregation/ Exchange / Join etc)
Signature Check and Biased Fuzzer Tests ( Expression / Aggregation)
Fuzzer Tests using Presto as source of truth
Docker Image build jobs
If an underlying dependency is changed, a new Docker CI image is built for
Ubuntu Linux
Centos
Presto Linux image
Documentation build and publish Job
If underlying documentation is changed, Velox documentation pages are rebuilt and published
Previous implementation of CI in CircleCI grew organically and was unoptimized, resulting in long build times, and also significantly costlier. This opportunity to migrate to Github Actions helped to take a holistic view of CI deployments and actively optimized to reduce build times and CI spend. Note however, that there has been continued investment in reducing test times to further improve Velox reliability, stability and developer experience. Some of the optimizations completed are:
Persisting build artifacts across builds: During every build, the object files and binaries produced are cached. In addition to this, artifacts such as scalar function signatures and aggregate function signatures are produced. These signatures are used to compare with the baseline version, by comparing against the changes in the current PR to determine if the current changes are backwards incompatible or bias the newly added changes. Using a stash to persist these artifacts helps save one build cycle.
Optimizing our Instances: Building Velox is Memory and CPU intensive job. Some beefy instances (16-core machines) are used to build Velox. After the build, the build artifacts are copied to smaller instances (4 core machines) to run fuzzer tests and other jobs. Since these fuzzers often run for an hour and are less intensive than the build process, it resulted in significant CI savings while increasing the test coverage.
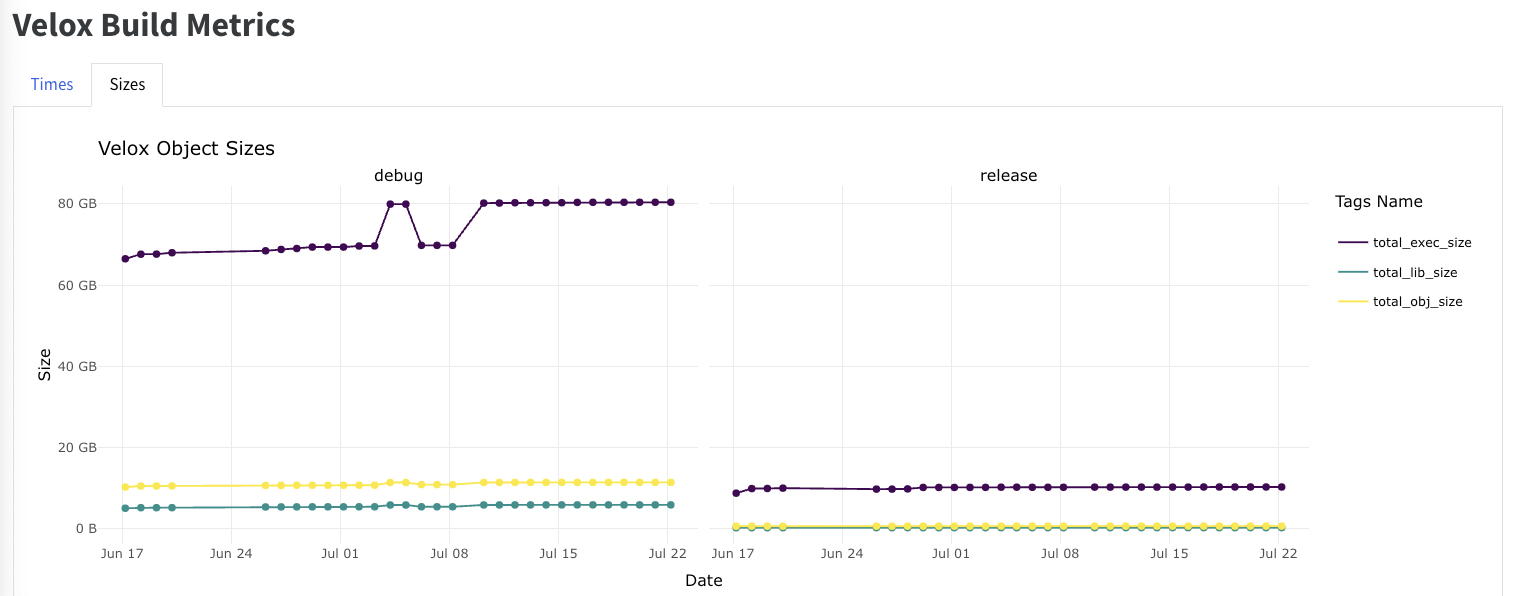
Velox CI builds were instrumented in Conbench so that it can capture various metrics about the builds:
Build times at translation unit / library/ project level.
Binary sizes produced at TLU/ .a,.so / executable level.
Memory pressure
Measure across time how our changes affect binary sizes
A nightly job is run to capture these build metrics and it is uploaded to Conbench. Velox build metrics report is available here: Velox Build Metrics Report
A large part of the credit goes to Jacob Wujciak and the team at Voltron Data. We would also like to thank other collaborators in the Open Source Community and at Meta, including but not limited to:
Meta: Sridhar Anumandla, Pedro Eugenio Rocha Pedreira, Deepak Majeti, Meta OSS Team, and others
Voltron Data: Jacob Wujciak, Austin Dickey, Marcus Hanwell, Sri Nadukudy, and others
Queries that use TRY or TRY_CAST may experience poor performance and high CPU
usage due to excessive exception throwing. We optimized CAST to indicate
failure without throwing and introduced a mechanism for scalar functions to do
the same. Microbenchmark measuring worst case performance of CAST improved
100x. Samples of production queries show 30x cpu time improvement.
TRY construct can be applied to any expression to suppress errors and turn them
into NULL results. TRY_CAST is a version of CAST that suppresses errors and
returns NULL instead.
For example, parse_datetime('2024-05-', 'YYYY-MM-DD') fails:
Invalid format: "2024-05-" is too short
, but TRY(parse_datetime('2024-05-', 'YYYY-MM-DD')) succeeds and returns NULL.
Similarly, CAST('foo' AS INTEGER) fails:
Cannot cast 'foo' to INT
, but TRY_CAST('foo' AS INTEGER) succeeds and returns NULL.
TRY can wrap any expression, so one can wrap CAST as well:
TRY(CAST('foo' AS INTEGER))
Wrapping CAST in TRY is similar to TRY_CAST, but not equivalent. TRY_CAST
suppresses only cast errors, while TRY suppresses any error in the expression
tree.
For example, CAST(1/0 AS VARCHAR) fails:
Division by zero
, TRY_CAST(1/0 AS VARCHAR) also fails:
Division by zero
, but TRY(CAST(1/0 AS VARCHAR)) succeeds and returns NULL.
In this case, the error is generated by division operation (1/0). TRY_CAST
cannot suppress that error, but TRY can. More generally, TRY(CAST(...))
suppresses all errors in all expressions that are evaluated to produce
an input for CAST as well as errors in CAST itself, but TRY_CAST suppresses
errors in CAST only.
In most cases only a fraction of rows generates an error. However, there are
queries where a large percentage of rows fail. In these cases, a lot of CPU
time goes into handling exceptions.
For example, one Prestissimo query used 3 weeks of CPU time, 93% of
which was spent processing try(date_parse(...)) expressions where most rows
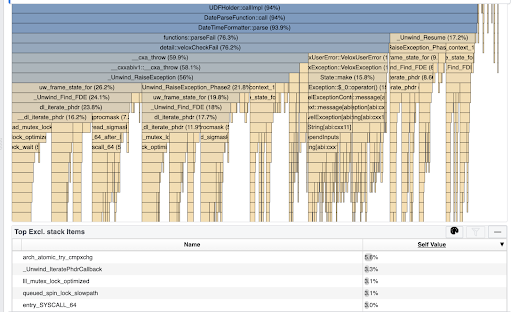
failed. Here is a profile for that query that shows that all the time went into
stack unwinding:
This query processes 14B rows, ~70% of which fail in date_parse(...) function
due to the date string being empty.
presto> select try(date_parse('', '%Y-%m-%d')); _col0 ------- NULL (1 row) – TRY suppressed Invalid format: "" error and produced a NULL.
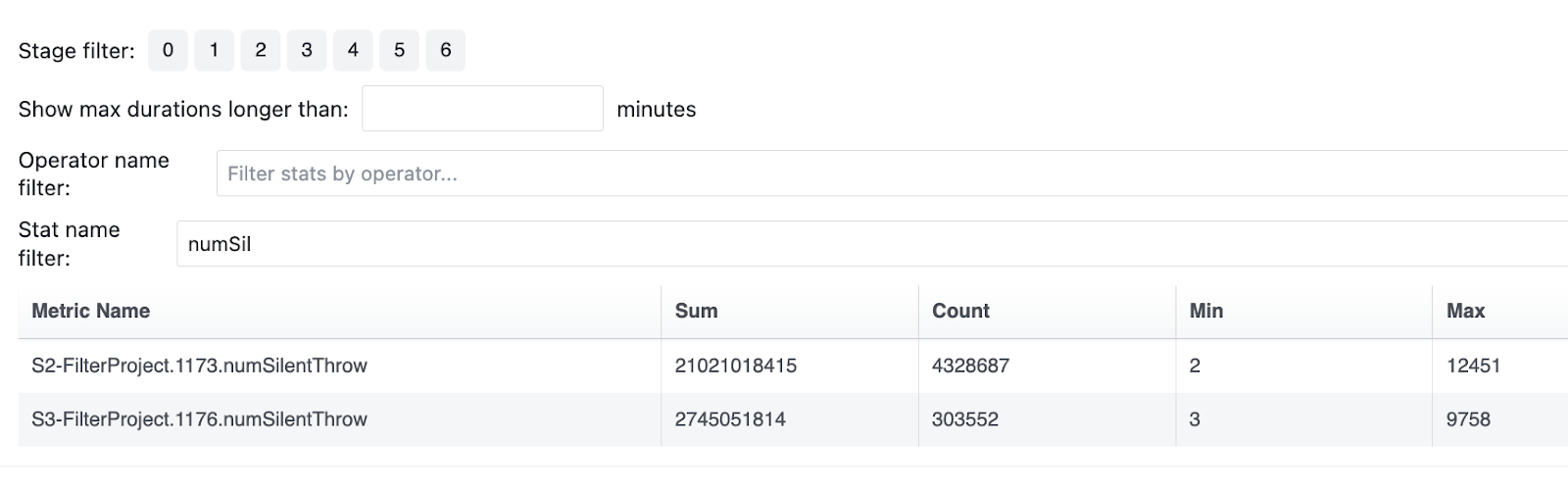
Velox tracks the number of suppressed exceptions per operator / plan node and
reports these as numSilentThrow runtime stat. For this query, Velox reported
21B throws for a single FilterProject node that processed 14B rows. Before the
optimizations, each failing row used to throw twice. An earlier blog post
from Laith Sakka explains why.
After the optimizations this query’s CPU time dropped
to 17h: 30x difference from the original cpu time. Compared to
Presto Java, this query uses 4x less cpu time (originally it used 6x more).
We observed similar issues with queries that use other functions that parse
strings as well as casts from strings.
To avoid the performance penalty of throwing exceptions we need to report errors
differently. Google’s Abseil library uses absl::Status to return errors from
void functions and absl::StatusOr to return value or error from non-void
functions. Arrow library
has similar Status and Result. Our own Folly has folly::Expected.
Inspired by these examples we introduced velox::Status and velox::Expected.
velox::Status holds a generic error code and an error message.
velox::Expected<T> is a typedef for folly::Expected<T, velox::Status>.
For example, a non-throwing modulo operation can be implemented like this:
Expected<int> mod(int a, int b) { if (b == 0) { return folly::makeUnexpected(Status::UserError(“Division by zero”)); } return a % b; }
We extended the Simple Function API to allow authoring non-throwing scalar
functions. The function author can now define a ‘call’ method that returns
Status. Such a function can indicate an error by returning a non-OK status.
Status call(result&, arg1, arg2,..)
These functions are still allowed to throw and exceptions will be handled
properly, but not throwing improves performance of expressions that use TRY.
Modulo SQL function would look like this:
template <typename TExec> struct NoThrowModFunction { VELOX_DEFINE_FUNCTION_TYPES(TExec); Status call(int64_t& result, const int64_t& a, const int64_t& b) { if (b == 0) { return Status::UserError("Division by zero"); } result = a % b; return Status::OK(); } };
We changed date_parse, parse_datetime, and from_iso8601_date Presto functions
to use the new API and report errors without throwing.
Vector functions can implement non-throwing behavior by leveraging the new
EvalCtx::setStatus(row, status) API. However, nowadays we expect virtually all
functions to be written using Simple Function API.
CAST is complex. A single name refers to multiple dozen individual operations.
The full matrix of supported conversions is available in the Velox
documentation. Not all casts throw. For example, cast from an integer to a
string does not throw. However, casts from strings may fail in multiple ways. A
common failure scenario is cast from an empty string. Laith Sakka optimized
this use case earlier.
> select cast('' as integer); Cannot cast '' to INT
However, we are also seeing failures in casting non-empty strings and NaN floating point values to integers.
> select cast(nan() as bigint); Unable to cast NaN to bigint > select cast('123x' as integer); Cannot cast '123x' to INT
CAST from string to integer and floating point value is implemented using
folly::to template. Luckily there is a non-throwing version: folly::tryTo.
We changed our CAST implementation to use folly::tryTo to avoid throwing.
Not throwing helped improve performance of TRY_CAST by 20x.
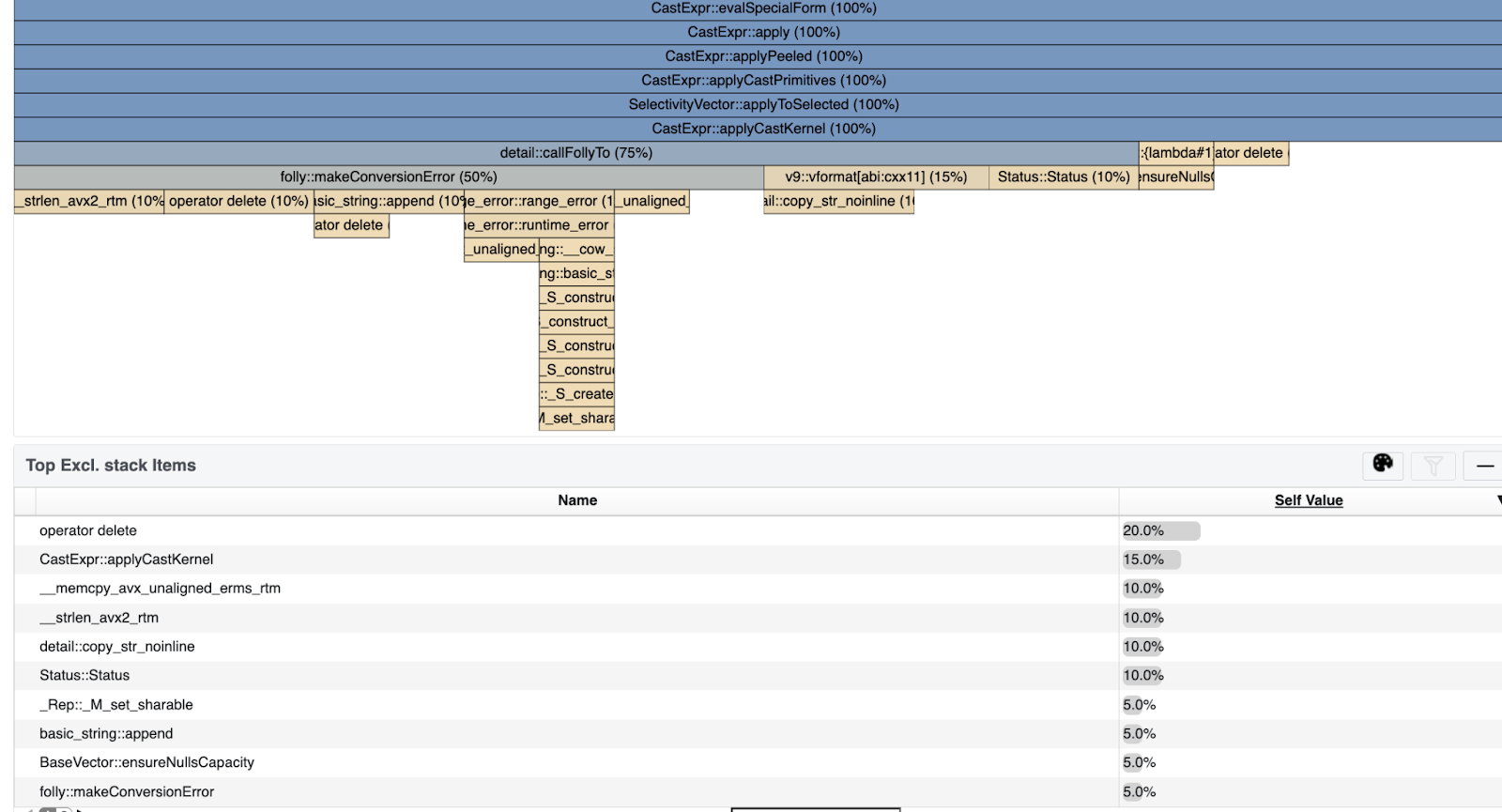
Still, the profile showed that there is room for further improvement.
After switching to non-throwing implementation, the profile showed that half the
cpu time went into folly::makeConversionError. folly::tryTo returns result or
ConversionCode enum. CAST uses folly::makeConversionError to convert
ConversionCode into a user-friendly error message. This involves allocating and
populating a string for the error message, copying it into the std::range_error
object, then copying it again into Status. This error message is very helpful
if it is being propagated all the way to the user, but it is not needed if the
error is suppressed via TRY or TRY_CAST.
To solve this problem we introduced a thread-local flag, threadSkipErrorDetails,
that indicates whether Status needs to include a detailed error message or not.
By default, this flag is ‘false’, but TRY and TRY_CAST set it to ‘true’. CAST
logic checks this flag to decide whether to call folly::makeConversionError or
not. This change gives a 3x performance boost to TRY_CAST and 2x
to TRY.
After this optimization, we observed that TRY(CAST(...)) is up to 5x slower than
TRY_CAST when many rows fail.
The profile revealed that 30% of cpu time went to
EvalCtx::ensureErrorsVectorSize. For every row that fails, we call
EvalCtx::ensureErrorsVectorSize to resize the error vector to accommodate that
row. When many rows fail we end up resizing a lot: resize(1), resize(2),
resize(3),...resize(n). We fixed this by pre-allocating the error vector in the TRY
expression.
Another 30% of cpu time went into managing reference counts for
std::shared_ptr<std::exception_ptr> stored in the errors vector. We do not need
error details for TRY, hence, no need to store these values. We fixed this by
making error values in error vector optional and updating EvalCtx::setStatus to
skip writing these under TRY.
After all these optimizations, the microbenchmark that measures performance of
casting invalid strings into integers showed 100x improvement. The benchmark
evaluates 4 expressions:
We can identify queries with a high percentage of numSilentThrow rows and
change throwing functions to not throw.
For simple functions this involves changing the ‘call’ method to return Status
and replacing ‘throw’ statements with return Status::UserError(...). You get
extra points for producing error messages conditionally based on thread-local
flag threadSkipErrorDetails().
template <typename TExec> struct NoThrowModFunction { VELOX_DEFINE_FUNCTION_TYPES(TExec); Status call(int64_t& result, const int64_t& a, const int64_t& b) { if (b == 0) { If (threadSkipErrorDetails()) { return Status::UserError(); } return Status::UserError("Division by zero"); } result = a % b; return Status::OK(); } };
We are changing CAST(varchar AS date) to not throw.
We provided a non-throwing ‘call’ API for simple functions that never return a
NULL for a non-NULL input. This covers the majority of Presto functions. For
completeness, we would want to provide non-throwing ‘call’ APIs for all other
use cases:
bool call() for returning NULL sometimes
callAscii for processing all-ASCII inputs
callNullable for processing possibly NULL inputs
callNullFree for processing complex inputs with all NULLs removed.
LIKE is a very useful SQL operator. It is used to do string pattern matching. The following examples for LIKE usage are from the Presto doc:
SELECT * FROM (VALUES ('abc'), ('bcd'), ('cde')) AS t (name) WHERE name LIKE '%b%' --returns 'abc' and 'bcd' SELECT * FROM (VALUES ('abc'), ('bcd'), ('cde')) AS t (name) WHERE name LIKE '_b%' --returns 'abc' SELECT * FROM (VALUES ('a_c'), ('_cd'), ('cde')) AS t (name) WHERE name LIKE '%#_%' ESCAPE '#' --returns 'a_c' and '_cd'
These examples show the basic usage of LIKE:
Use % to match zero or more characters.
Use _ to match exactly one character.
If we need to match % and _ literally, we can specify an escape char to escape them.
When we use Velox as the backend to evaluate Presto's query, LIKE operation is translated
into Velox's function call, e.g. name LIKE '%b%' is translated to
like(name, '%b%'). Internally Velox converts the pattern string into a regular
expression and then uses regular expression library RE2
to do the pattern matching. RE2 is a very good regular expression library. It is fast
and safe, which gives Velox LIKE function a good performance. But some popularly used simple patterns
can be optimized using direct simple C++ string functions instead of regex.
e.g. Pattern hello% matches inputs that start with hello, which can be implemented by direct memory
comparison of prefix ('hello' in this case) bytes of input:
// Match the first 'length' characters of string 'input' and prefix pattern. bool matchPrefixPattern( StringView input, const std::string& pattern, size_t length) { return input.size() >= length && std::memcmp(input.data(), pattern.data(), length) == 0; }
It is much faster than using RE2. Benchmark shows it gives us a 750x speedup. We can do similar
optimizations for some other patterns:
%hello: matches inputs that end with hello. It can be optimized by direct memory comparison of suffix bytes of the inputs.
%hello%: matches inputs that contain hello. It can be optimized by using std::string_view::find to check whether inputs contain hello.
These simple patterns are straightforward to optimize. There are some more relaxed patterns that
are not so straightforward:
hello_velox%: matches inputs that start with 'hello', followed by any character, then followed by 'velox'.
%hello_velox: matches inputs that end with 'hello', followed by any character, then followed by 'velox'.
%hello_velox%: matches inputs that contain both 'hello' and 'velox', and there is a single character separating them.
Although these patterns look similar to previous ones, but they are not so straightforward
to optimize, _ here matches any single character, we can not simply use memory comparison to
do the matching. And if user's input is not pure ASCII, _ might match more than one byte which
makes the implementation even more complex. Also note that the above patterns are just for
illustrative purpose. Actual patterns can be more complex. e.g. h_e_l_l_o, so trivial algorithm
will not work.
We optimized these patterns as follows. First, we split the patterns into a list of sub patterns, e.g.
hello_velox% is split into sub-patterns: hello, _, velox, %, because there is
a % at the end, we determine it as a kRelaxedPrefix pattern, which means we need to do some prefix
matching, but it is not a trivial prefix matching, we need to match three sub-patterns:
kLiteralString: hello
kSingleCharWildcard: _
kLiteralString: velox
For kLiteralString we simply do a memory comparison:
Note that since it is a memory comparison, it handles both pure ASCII inputs and inputs that
contain Unicode characters.
Matching _ is more complex considering that there are variable length multi-bytes character in
unicode inputs. Fortunately there are existing libraries which provides unicode related operations: utf8proc.
It provides functions that tells us whether a byte in input is the start of a character or not,
how many bytes current character consists of etc. So to match a sequence of _ our algorithm is:
if (subPattern.kind == SubPatternKind::kSingleCharWildcard) { // Match every single char wildcard. for (auto i = 0; i < subPattern.length; i++) { if (cursor >= input.size()) { return false; } auto numBytes = unicodeCharLength(input.data() + cursor); cursor += numBytes; } }
Here:
cursor is the index in the input we are trying to match.
unicodeCharLength is a function which wraps utf8proc function to determine how many bytes current character consists of.
So the logic is basically repeatedly calculate size of current character and skip it.
It seems not that complex, but we should note that this logic is not effective for pure ASCII input.
Every character is one byte in pure ASCII input. So to match a sequence of _, we don't need to calculate the size
of each character and compare in a for-loop. In fact, we don't need to explicitly match _ for pure ASCII input as well.
We can use the following logic instead:
It only matches the kLiteralString pattern at the right position of the inputs, _ is automatically
matched(actually skipped). No need to match it explicitly. With this optimization we get 40x speedup
for kRelaxedPrefix patterns, 100x speedup for kRelaxedSuffix patterns.
Thank you Maria Basmanova for spending a lot of time
reviewing the code.
Reduce_aggis the only lambda aggregate Presto function. It allows users to define arbitrary aggregation logic using 2 lambda functions.
reduce_agg(inputValue T, initialState S, inputFunction(S, T, S), combineFunction(S, S, S)) → S Reduces all non-NULL input values into a single value. inputFunction will be invoked for each non-NULL input value. If all inputs are NULL, the result is NULL. In addition to taking the input value, inputFunction takes the current state, initially initialState, and returns the new state. combineFunction will be invoked to combine two states into a new state. The final state is returned. Throws an error if initialState is NULL or inputFunction or combineFunction returns a NULL.
Once can think of reduce_agg as using inputFunction to implement partial aggregation and
combineFunction to implement final aggregation. Partial aggregation processes a list of
input values and produces an intermediate state:
auto s = initialState; for (auto x : input) { s = inputFunction(s, x); } return s;
Final aggregation processes a list of intermediate states and computes the final state.
auto s = intermediates[0]; for (auto i = 1; i < intermediates.size(); ++i) s = combineFunction(s, intermediates[i]); } return s;
For example, one can implement SUM aggregation using reduce_agg as follows:
reduce_agg(c, 0, (s, x) -> s + x, (s, s2) -> s + s2)
Implementation of AVG aggregation is a bit trickier. For AVG, state is a tuple of sum and
count. Hence, reduce_agg can be used to compute (sum, count) pair, but it cannot compute
the actual average. One needs to apply a scalar function on top of reduce_agg to get the
average.
SELECT id, sum_and_count.sum / sum_and_count.count FROM ( SELECT id, reduce_agg(value, CAST(row(0, 0) AS row(sum double, count bigint)), (s, x) -> CAST(row(s.sum + x, s.count + 1) AS row(sum double, count bigint)), (s, s2) -> CAST(row(s.sum + s2.sum, s.count + s2.count) AS row(sum double, count bigint))) AS sum_and_count FROM t GROUP BY id );
The examples of using reduce_agg to compute SUM and AVG are for illustrative purposes.
One should not use reduce_agg if a specialized aggregation function is available.
One use case for reduce_agg we see in production is to compute a product of input values.
reduce_agg(c, 1.0, (s, x) -> s * x, (s, s2) -> s * s2)
Another example is to compute a list of top N distinct values from all input arrays.
reduce_agg(x, array[], (a, b) -> slice(reverse(array_sort(array_distinct(concat(a, b)))), 1, 1000), (a, b) -> slice(reverse(array_sort(array_distinct(concat(a, b)))), 1, 1000))
Note that this is equivalent to the following query:
SELECT array_agg(v) FROM ( SELECT DISTINCT v FROM t, UNNEST(x) AS u(v) ORDER BY v DESC LIMIT 1000 )
Efficient implementation of reduce_agg lambda function is not straightforward. Let’s
consider the logic for partial aggregation.
auto s = initialState; for (auto x : input) { s = inputFunction(s, x); }
This is a data-dependent loop, i.e. the next loop iteration depends on the results of
the previous iteration. inputFunction needs to be invoked on each input value x
separately. Since inputFunction is a user-defined lambda, invoking inputFunction means
evaluating an expression. And since expression evaluation in Velox is optimized for
processing large batches of values at a time, evaluating expressions on one value at
a time is very inefficient. To optimize the implementation of reduce_agg we need to
reduce the number of times we evaluate user-defined lambdas and increase the number
of values we process each time.
One approach is to
convert all input values into states by evaluating inputFunction(initialState, x);
split states into pairs and evaluate combineFunction on all pairs;
repeat step (2) until we have only one state left.
Let’s say we have 1024 values to process. Step 1 evaluates inputFunction expression
on 1024 values at once. Step 2 evaluates combineFunction on 512 pairs, then on 256
pairs, then on 128 pairs, 64, 32, 16, 8, 4, 2, finally producing a single state.
Step 2 evaluates combineFunction 9 times. In total, this implementation evaluates
user-defined expressions 10 times on multiple values each time. This is a lot more
efficient than the original implementation that evaluates user-defined expressions
1024 times.
In general, given N inputs, the original implementation evaluates expressions N times
while the new one log2(N) times.
Note that in case when N is not a power of two, splitting states into pairs may leave
an extra state. For example, splitting 11 states produces 5 pairs + one extra state.
In this case, we set aside the extra state, evaluate combineFunction on 5 pairs, then
bring extra state back to a total of 6 states and continue.
A benchmark, velox/functions/prestosql/aggregates/benchmarks/ReduceAgg.cpp, shows that
initial implementation of reduce_agg is 60x slower than SUM, while the optimized
implementation is only 3x slower. A specialized aggregation function will always be
more efficient than generic reduce_agg, hence, reduce_agg should be used only when
specialized aggregation function is not available.
Finally, a side effect of the optimized implementation is that it doesn't support
applying reduce_agg to sorted inputs. I.e. one cannot use reduce_agg to compute an
equivalent of
SELECT a, array_agg(b ORDER BY b) FROM t GROUP BY 1
The array_agg computation depends on order of inputs. A comparable implementation
using reduce_agg would look like this:
SELECT a, reduce_agg(b, array[], (s, x) -> concat(s, array[x]), (s, s2) -> concat(s, s2) ORDER BY b) FROM t GROUP BY 1
To respect ORDER BY b, the reduce_agg would have to apply inputFunction to each
input value one at a time using a data-dependent loop from above. As we saw, this
is very expensive. The optimization we apply does not preserve the order of inputs,
hence, cannot support the query above. Note that
Presto doesn't support applying reduce_agg to sorted inputs either.
One of the queries shadowed internally at Meta was much slower in Velox compared to presto(2 CPU days vs. 4.5 CPU hours). Initial investigation identified that the overhead is related to casting empty strings inside a try_cast.
In this blogpost I summarize my learnings from investigating and optimizing try_cast.
name total time try_cast(empty_string_col as int) 4.88s try_cast(valid_string_col as int) 2.15ms
The difference between casting a valid and invalid input is huge (>1000X), although ideally casting an invalid string should be
just setting a null and should not be that expensive.
Benchmark results after optimization:
name total time try_cast(empty_string_col as int) 1.24ms try_cast(valid_string_col as int) 2.15ms
The investigation revealed several factors that contributed to the huge gap, summarized in the points below in addition to
their approximate significance.
Error logs overhead.
Whenever a VeloxUserError is thrown an error log used to be generated, however those errors are expected to, (1) either get converted to null if is
thrown from within a try, (2) or show up to the user otherwise. Hence, no need for that expensive logging .
Moreover, each failing row used to generate two log message because VELOX_USER_FAIL was called twice. Disabling logging for user error helped save 2.6s of the 4.88s.
Throwing overhead.
Each time a row is casted four exception were thrown:
From within Folly library.
From Cast in Conversions.h, the function catch the exception thrown by Folly and convert it to Velox exception and throw it.
From castToPrimitive function, which catch the exception and threw a new exception with more context.
Finally, a forth throw came from applyToSelectedNoThrow which caught an exception and called toVeloxException
to check exception type and re-throw.
Those are addressed and avoided using the following:
When the input is an empty string, avoid calling folly by directly checking if the input is empty.
Remove the catch and re-throw from Conversions.h
Introduce setVeloxExceptionError, which can be used to set the error directly in evalContext without throwing (does not call toVeloxException).
Optimize applyToSelectedNoThrow to call setVeloxExceptionError if it catches Velox exception.
With all those changes throwing exceptions is completely avoided when casting empty strings. This takes the runtime down to 382.07ms,
but its still much higher than 2.15ms.
Velox exception construction overhead.
Constructing Velox exception is expensive, even when there is no throw at all! Luckily this can be avoided for try_cast, since
the output can be directly set to null without having to use the errorVector to track errors. By doing so the benchmark runtime goes
down to 1.24ms.
After all the changes we have the following performance numbers for other patterns of similar expressions
(much better than before but still can be optimized a lot).
try_cast(empty_string_col as int) 1.24ms 808.79 try_cast(invalid_string_col as int) 393.61ms 2.54 try(cast(empty_string_col as int)) 375.82ms 2.66 try(cast(invalid_string_col as int)) 767.74ms 1.30
All these can be optimized to have the same runtime cost of the first expression 1.24ms.
To do that two thing are needed:
1) Tracking errors for try, should not require constructing exceptions
The way errors are tracked when evaluating a try expression is by setting values in an ErrorVector; which is a vector of VeloxException pointers.
This forces the construction of a Velox exception for each row, but that is not needed (for try expressions) since only row numbers need to be
tracked to be converted eventually to nulls, but not the actual errors.
This can be changed such that errors are tracked using a selectivity vector. Its worth noting that for other expressions such as conjunct
expressions this tracking is needed, hence we need to distinguish between both.
This would help optimize any try(x) expression where x throws for large number of rows.
2)Use throw-free cast library
Avoiding throw and instead returning a boolean should allow us to directly set null in try_cast and avoid construction of exceptions completely.
While this is done now for empty strings, its not done for all other types of errors. Folly provides a non-throwing API (folly::tryTo) that can be tried for that purpose.
folly::tryTo. According to the folly documentation On the error path, you can expect tryTo to be roughly three orders of magnitude faster than the throwing to and to completely avoid any lock contention arising from stack unwinding.
This is all very nice and convenient, but there is a catch.
The documentation says that the "comparator will take two nullable arguments representing two
nullable elements of the array."" Did you notice the word "nullable" in "nullable arguments"
and "nullable elements"? Do you think it is important? It is Ok if the answer is No or Not Really.
Turns out this "nullable" thing is very important. The comparator is expected to handle null
inputs and should not assume that inputs are not null or that nulls are handled automatically.
Why is it important to handle null inputs? Let’s see what happens if the comparator doesn’t
handle nulls.
presto> select array_sort(array[2, 3, null, 1], (x, y) -> if (x < y, -1, if (x > y, 1, 0))); _col0 ----------------- [2, 3, null, 1]
The result array is not sorted! If subsequent logic relies on the array to be sorted the query
will silently return wrong results. And if there is no logic that relies on the sortedness of
the array then why waste CPU cycles on sorting?
Why is the array not sorted? That’s because the comparator returns 0 whenever x or y is null.
x < y returns null if x or y is null, then x > y returns null if x or y is null, then result is 0
This confuses the sorting algorithm as it sees that 1 == null, 2 == null, 3 == null,
but 1 != 2 and 1 != 3. The algorithm assumes that the comparator function is written correctly,
e.g. if a < b then b > a and if a == b and b == c then a == c. Comparator function that doesn’t
handle nulls does not satisfy these rules and causes unpredictable results.
To handle null inputs, the comparator function needs to be modified, for example, like so:
(x, y) -> CASE WHEN x IS NULL THEN 1 WHEN y IS NULL THEN -1 WHEN x < y THEN -1 WHEN x > y THEN 1 ELSE 0 END
presto> select array_sort(array[2, 3, null, 1], -> (x, y) -> CASE WHEN x IS NULL THEN 1 -> WHEN y IS NULL THEN -1 -> WHEN x < y THEN -1 -> WHEN x > y THEN 1 -> ELSE 0 END -> ); _col0 ----------------- [1, 2, 3, null]
This is longer and harder to read, but the result array is sorted properly. The new
comparator says that null is greater than any other value, so null is placed at the
end of the array.
Note: When (x, y) return -1, the algorithm assumes that x <= y.
Writing comparators correctly is not easy. Writing comparators that handle null inputs
is even harder. Having no feedback when a comparator is written incorrectly makes it
yet harder to spot bugs and fix them before a query lands in production and starts
producing wrong results.
I feel that Presto’s array_sort function with a custom comparator is dangerous and hard
to use and I wonder if it makes sense to replace it with a safer, easier to use alternative.
array_sort(array(T), function(T, U)) -> array(T)
This version takes an array and a transform lambda function that specifies how to compute
sorting keys from the array elements.
To sort array of structs by one of the struct fields, one would write
We also added partial support for array_sort with a comparator lambda function. Expression
compiler in Velox analyzes the comparator expression to determine whether it can be re-written
to the alternative version of array_sort. If so, it re-writes the expression and evaluates it.
Otherwise, it throws an unsupported exception.
Why didn’t we implement full support for comparator lambda functions in array_sort? Actually,
we couldn’t think of an efficient way to do that in a vectorized engine. Velox doesn’t use code
generation and interprets expressions. It can do that efficiently if it can process data in large
batches. array_sort with custom comparator doesn’t lend itself well to such processing.
array_sort with a transform lambda works well in a vectorized engine. To process a batch of arrays,
Velox first evaluates the transform lambda on all the elements of the arrays, then sorts the results.
In this blogpost, we will discuss two major recent changes to the simple function interface to make its performance comparable to the vector function implementations for functions that produce or consume complex types (Arrays, Maps and Rows).
To show how much simpler simple functions are. The figure below shows a function NestedMapSum written in both the simple and vector interfaces. The function consumes a nested map and computes the summations of all values and keys.
Note that the vector function implementation is minimal without any special optimization (ex: vector reuse, fast path for flat inputs ..etc). Adding optimizations will make it even longer.
NestedMapSum function implemented using vector(left) and simple(right) interfaces.
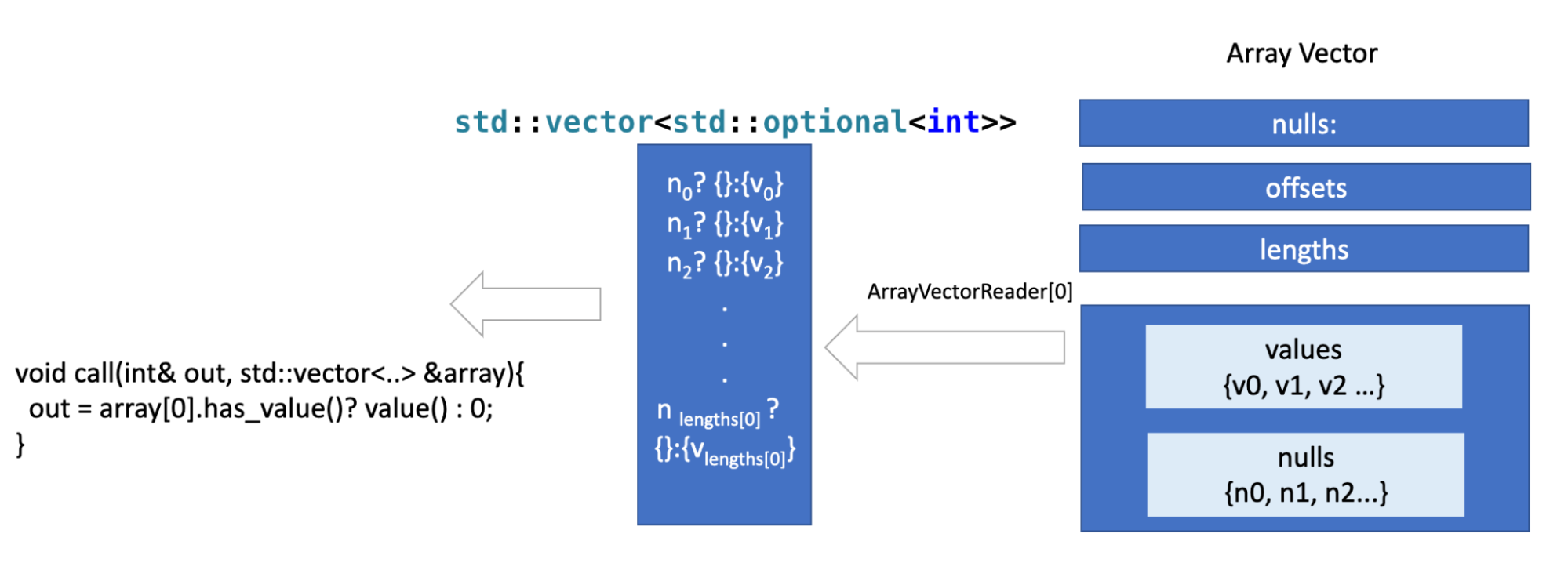
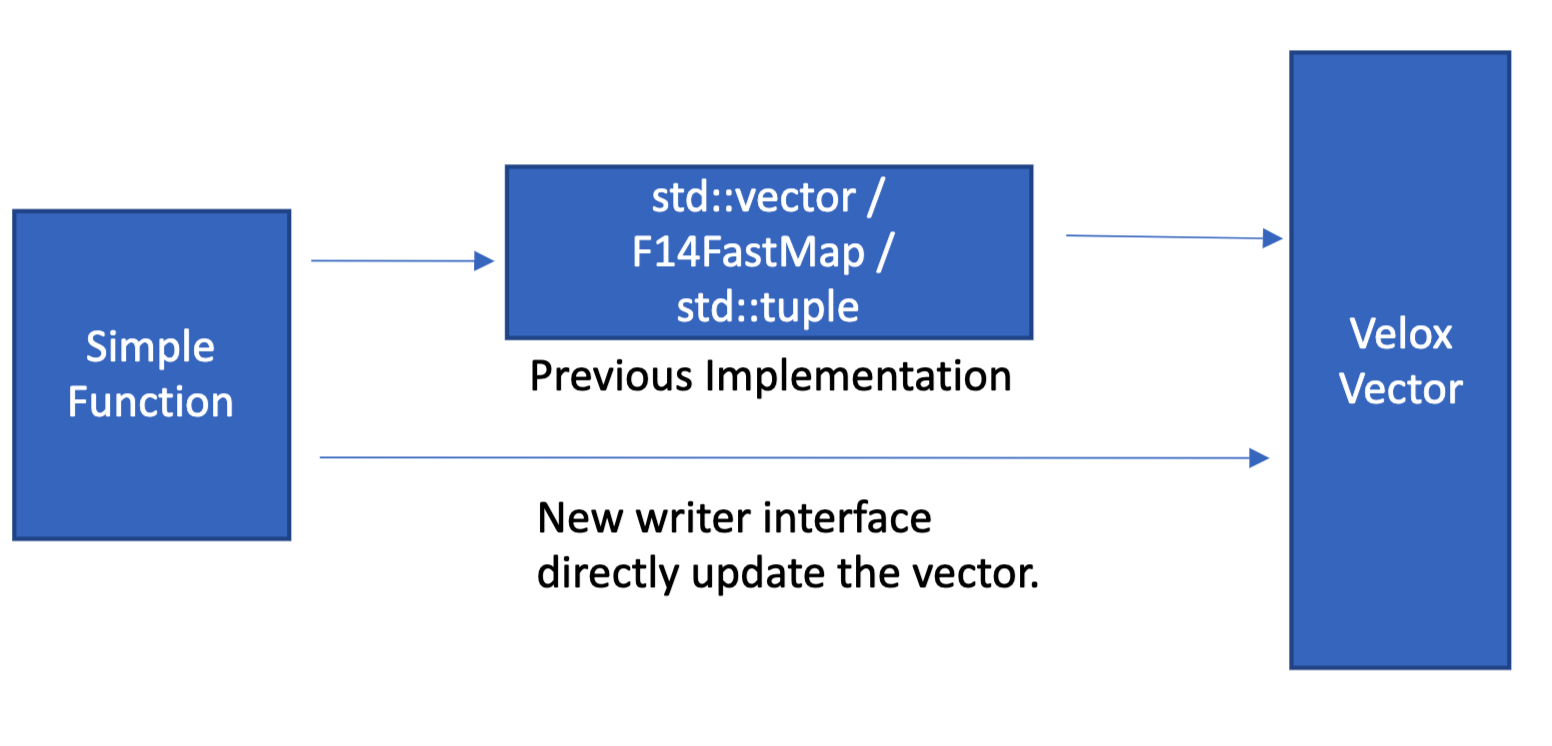
The previous representations of input complex types in the simple function interface were computationally expensive. Data from vectors used to be copied into std containers and passed to simple functions to process it. Arrays, Maps and Structs used to be materialized into std::vectors, folly::F14FastMap and std::tuples.
The graph below illustrates the previous approach.
The previous approach has two key inefficiencies; Eager materialization : For each row, all the data in the input vector is decoded and read before calling the function. And Double reading, the data is read twice once when the input is constructed, and again in the function when it's used.
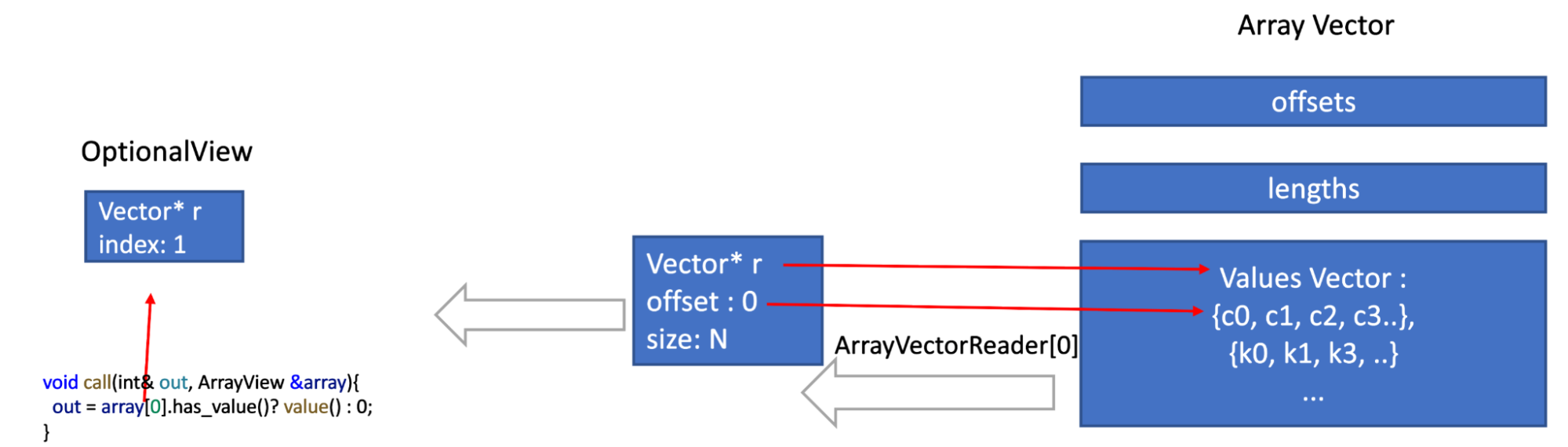
In order to mitigate those regressions, Velox introduced View types: ArraViews, MapViews ...etc. The goal is to keep the authoring simple but achieve at least the performance of a basic vector implementation that decodes input and applies some logic for every row without any special optimizations.
The view types are Lazy, very cheap to construct and do not materialize the underlying data unless the code accesses it.For example, the function array_first only needs to read the first element in every array, moreover the cardinality function does not need to read any elements in the array. They view types have interfaces similar to those of std::containers.
In a simplified form, an ArrayView stores the length and the offset of the array within the vector, in addition to a pointer to the elements array. Only when an element is accessed then an OptionalAccessor is created, which contains the index of the accessed element and a pointer
to the containing vector. Only when the user calls value() or has_value() on that accessor then the nullity or the value is read. Other view types are implemented in a similar way,
The graph below illustrates the process.
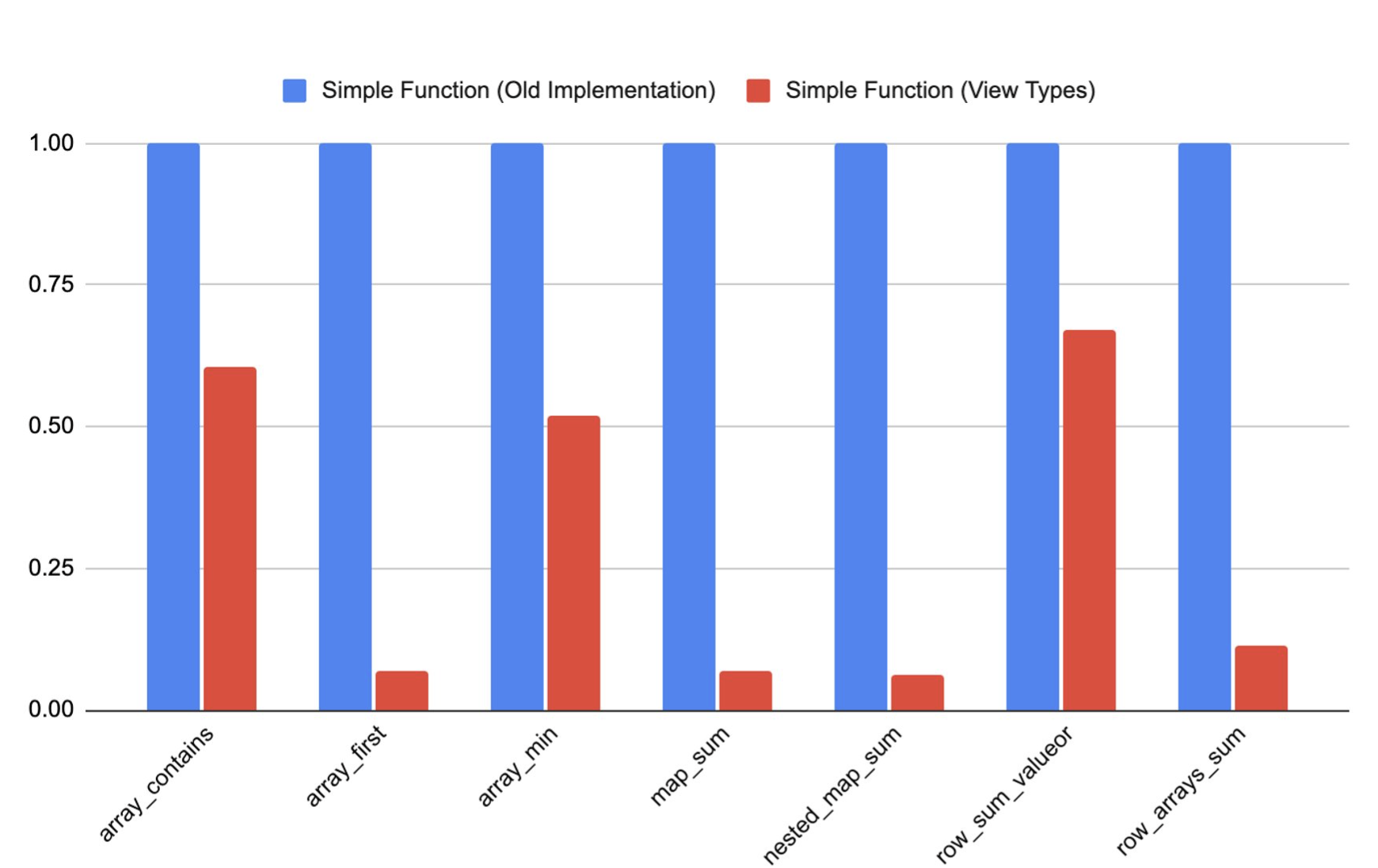
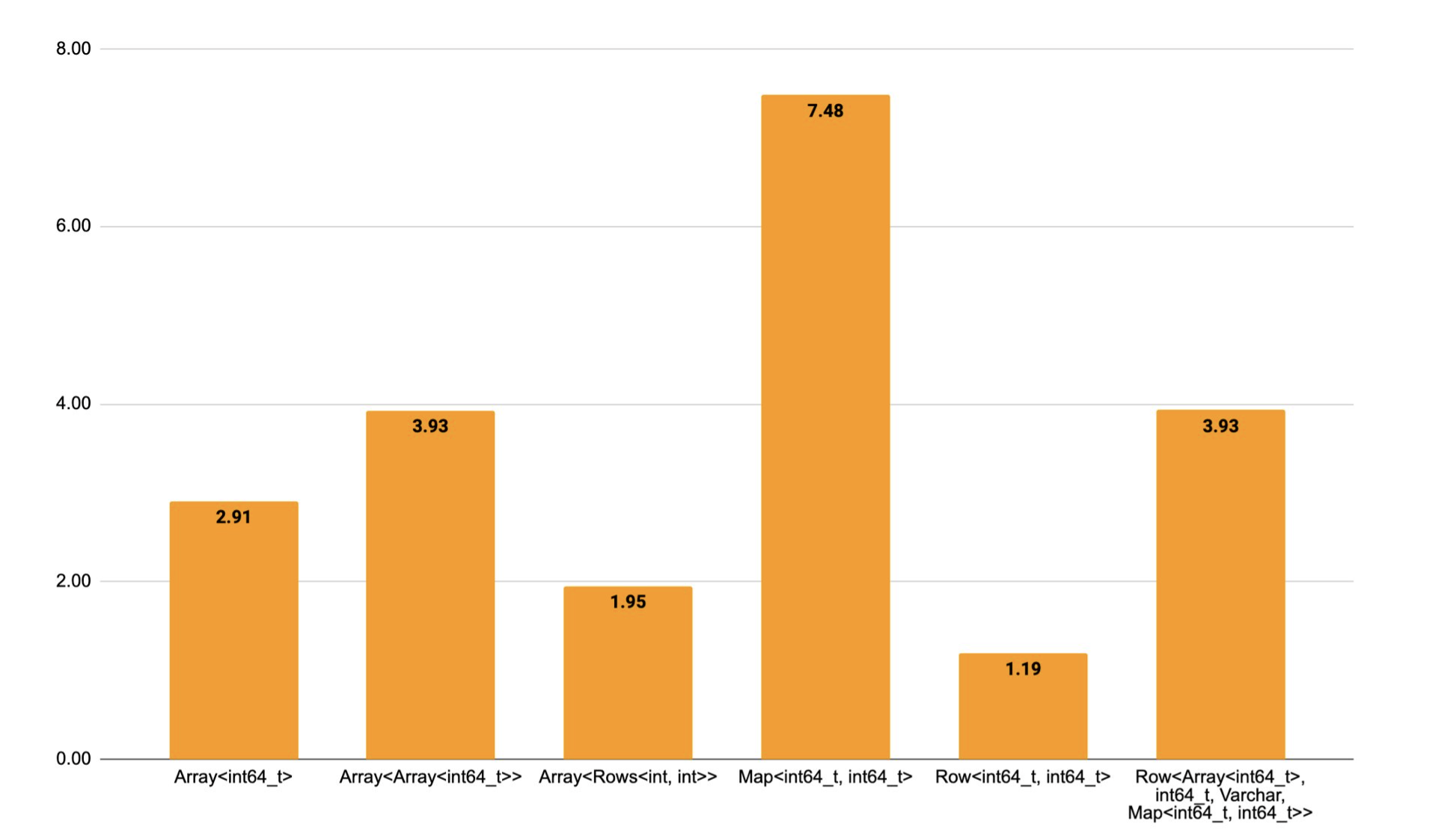
The graph below compares the runtime of some functions written in the simple interface before and after the introduction of the view types. The speedup for arrays is around 2X, for maps the speed is much higher > 10X because materializing the intermediate representation previously involves hashing the elements while constructing the hashmap. Furthermore, the overhead of materialization for nested complex types is very high as well, as reflected in row_arrays_sum.
Runtimes of functions before and after the introduction of view types, normalized to the runtime of the version that uses the view types.
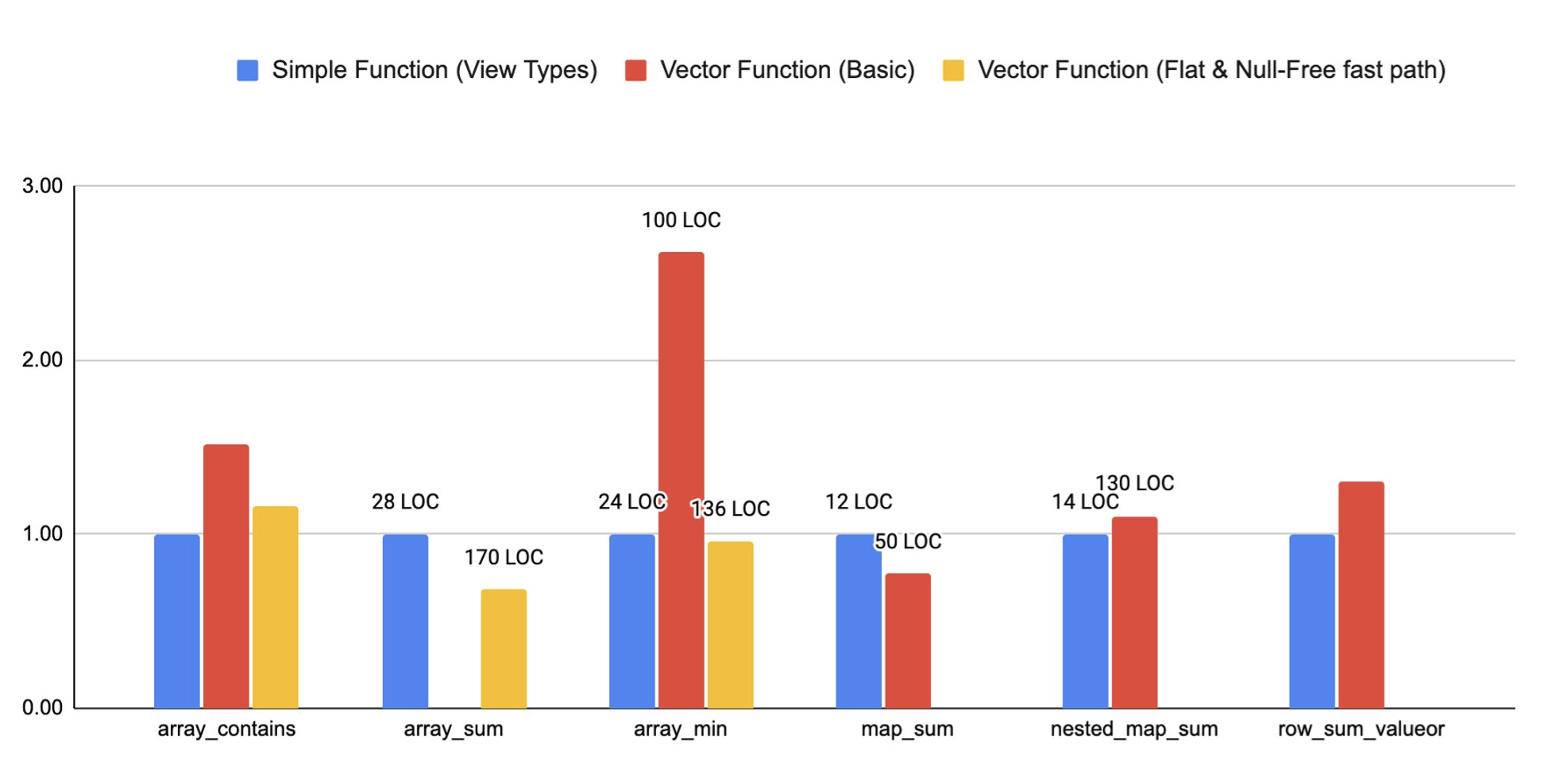
The graph below compares the runtimes of some functions written using the simple interface, a basic vector function implementation with no special optimizations for the non general case, and a vector implementation that is specialized for flat and null free. The bars are annotated with the line of codes (LOC) used to implement each function.
We can see that LOC are significantly lower for simple functions. ArraySum with flat and null free optimization is faster because the summation can be optimized much better when it's performed over a sequential array of data.
The reason the simple is faster than the vector for some benchmarks is because we have several optimizations in the simple interface that are not implemented in the basic vector versions.
A similar pattern of inefficiency existed for functions with complex output types. The graph below shows the previous path of writing complex types through the simple function interface. In the previous path, for each row, the result is first written to a temporary object (std::vector, folly::f14FastMap<>, etc.), then serialized into the Velox vector.
We changed the writing path so that the data is written directly into the Velox vector during the function evaluation. By introducing writer types: ArrayWriter, MapWriter, RowWriter. This avoids the double materialization and the unnecessary sorting and hashing for maps.
Consider the function below for example that constructs an array [0, n-1).
outerArray is an array writer and whenever push_back is called, the underlying vector array is updated directly and a new element is written to it.
In order & final elements writing: Unlike the previous interface, the new writer interface needs to write things in order, since it directly serializes elements into Velox vector buffers. Written elements also can not be modified.
For example, for a function with an Array<Map> output , we can't add three maps, and write to them concurrently. The new interface should enforce that one map is written completely before the next one starts. This is because we are serializing things directly in the map vector, and to determine the offset of the new map we need first to know the end offset of the previous one.
The code below shows a function with Array<Map> output:
Compatibility with std::like containers.: Unfortunately, the new interface is not completely compatible with std::like interfaces, in fact, it deviates syntactically and semantically (for example a std::map enforces unique keys and ordering of elements) while map writer does not.
When the element type is primitive (ex: Array<int>) we enable std::like APIs (push_back, emplace()).
But we can not do that for nested complex types (ex:Array<Array<int>>) since it breaks the in-order & final elements writing rule mentioned above.
The figure below shows the performance gain achieved by this change, functions' performance is evaluated before and after the change.
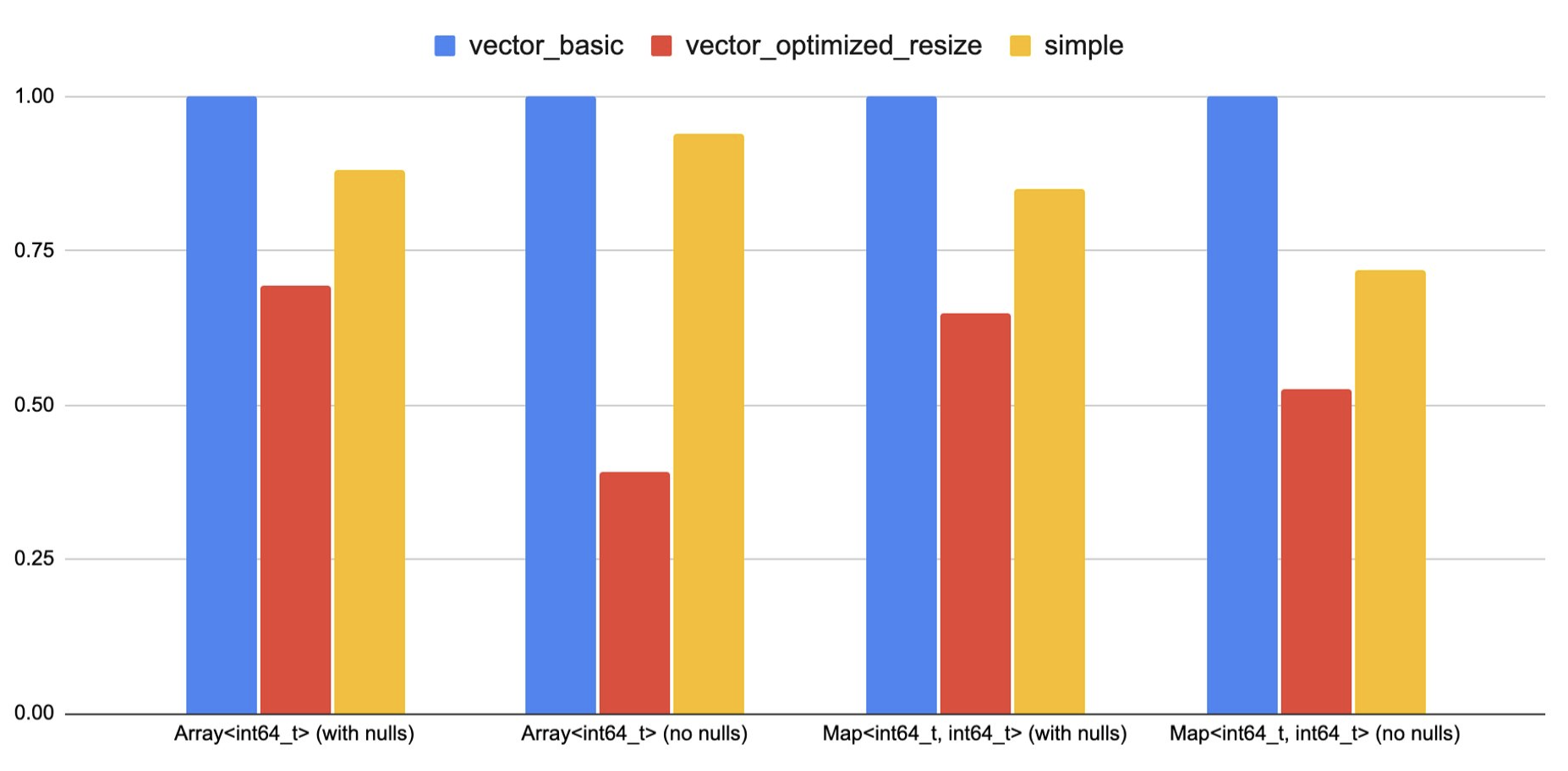
The chart below compares the performance of those functions with vector functions implementations, a vector function with an optimization that precomputes the total size needed for the output vector and a single resize is also added.
Note that those functions do almost no computation other than constructing the output map. Hence the resize cost becomes very critical, if those were doing more work, then its effect would be less.
Furthermore, the gap indicates that it might be worth it to add a way in the simple interface that enables pre-computing/resizing the output vector size.
When Velox was open sourced in August 2021, it was not nearly as easily usable and portable as it is today. In order for Velox to become the unified execution engine blurring the boundaries for data analytics and ML, we needed Velox to be easy to build and package on multiple platforms, and support a wide range of hardware architectures. If we are supporting all these platforms, we also need to ensure that Velox remains fast and regressions are caught early.
To improve the Velox experience for users and community developers, Velox has partnered with Voltron Data to help make Velox more accessible and user-friendly. In this blog post, we will examine the challenges we faced, the improvements that have already been made, and the ones yet to come.
Velox was a product of the mono repo and required installation of dependencies on the system via a script. Any change in the state of the host system could cause a build failure and introduce version conflicts of dependencies. Fixing these challenges was a big focus to help the Velox Community and we worked in collaboration with the Voltron Data Team. We wanted to improve the overall Velox user experience by making Velox easy to consume across a wide range of platforms to accelerate its adoption.
We choose hermetic builds as a solution to the aforementioned problems, as they provide a number of benefits. Hermetic builds1 improve reproducibility by providing isolation from the state of the host machine and produce the same result for any given commit in the Velox repository. This requires precise dependency management.
The first major step in moving towards hermetic builds was the integration of a new dependency management system that is able to download, configure and build the necessary dependencies within the Velox build process. This new system also gives users the option to use already installed system dependencies. We hope this work will increase adoption of Velox in downstream projects and make troubleshooting of build issues easier, as well as improve overall reliability and stability.
We also wanted to lower the barrier to entry for contributions to Velox. Therefore, we created Docker Development images for both Ubuntu and CentOS, and we now publish them automatically when changes are merged. We hope this work will help speed up the development process by allowing developers to stand up a development environment quickly, without the requirement of installing third-party dependencies locally. We also use these images in the Velox CI to lower build times and speed up the feedback loop for proposing a PR.
# Run the development image from the root of the Velox repository # to build and test Velox docker compose run --rm ubuntu-cpp
An important non-technical improvement is the introduction of new issue templates and utility scripts. These will help guide troubleshooting and getting support from the relevant Velox developers via Github. This helps to improve the experience for the community and make it easier for users and contributors to get help and support when they need it.
Lastly, we implemented new nightly builds to increase the overall reliability and stability of Velox, as well as test the integration with downstream community projects.
To enable easy access to Velox from Python, we built CI infrastructure to generate and publish pre-built binary wheels for PyVelox (the Velox Python Bindings). We also improved Conda support by contributing to upstream feedstocks.
We will continue the work of moving all dependencies to the new dependency management system to move closer to hermetic builds and make development and usage as smooth as possible.
In the same theme, the next major goal is the refactoring of the existing CMake build system to use a target based "modern" style. This will allow us to properly install Velox as a system library to be used by other projects. This project will improve the development experience overall by creating a stable, reliable build infrastructure, but also allows us to publish Velox as a conda-forge package and make it easier to further improve support for non x86_64 architectures like Apple Silicon, arm64 systems, various compilers and older CPUs that don’t support the currently obligatory instructions sets like BMI2 and make Velox available to an even larger community.
Confidence in the stability and reliability of a project are key when you want to deploy it as part of your stack. Therefore, we are working on a release process and versioning scheme for Velox so that you can deploy with confidence!
In conclusion, the collaboration between Velox and Voltron Data has led to several key improvements in Velox's packaging and CI. Setting up a new environment with Velox has never been this easy! With the new improvements, this new broader community of developers and contributors can expect a smoother and more user-friendly experience when using Velox. The Velox team is continuously working towards further improving the developer and user experience, and we invite you to join us in building the next generation unified execution engine!
Hermeticity - why hermetic builds are recommended↩
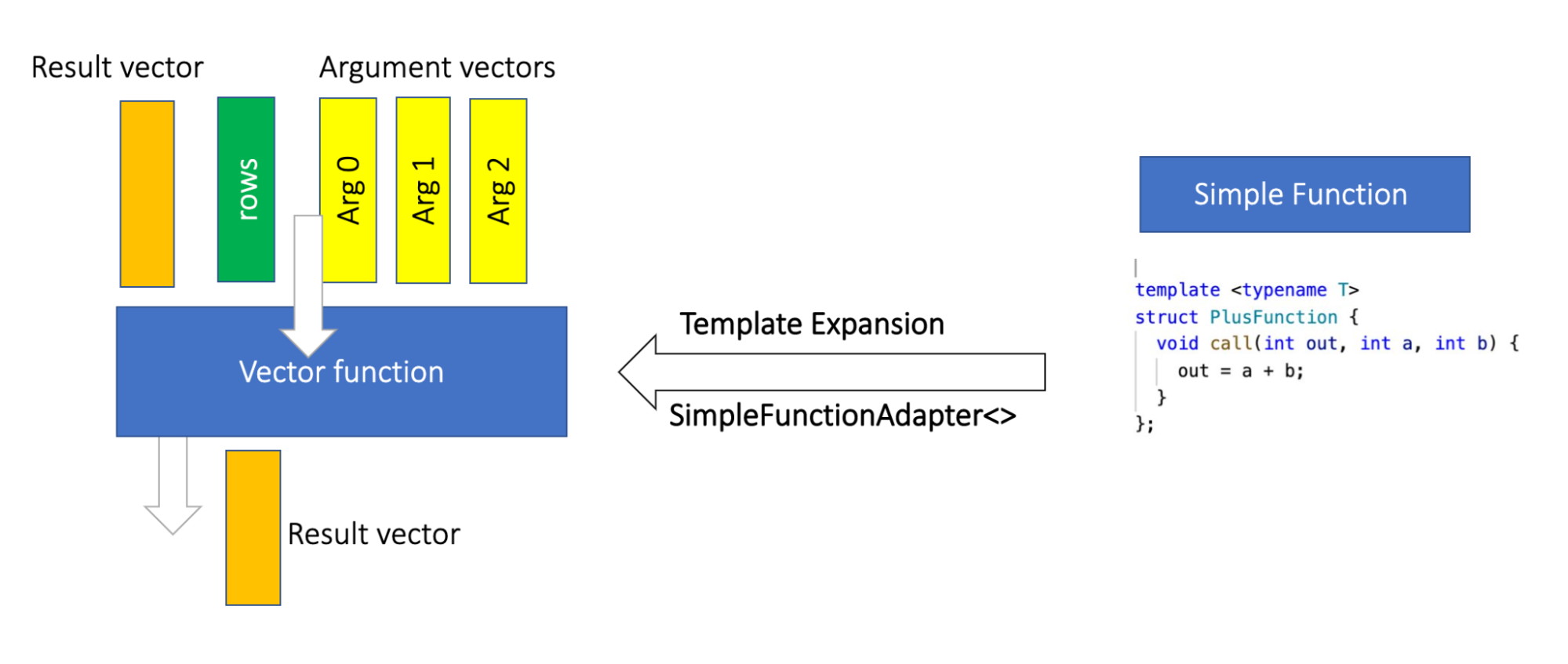
Scalar functions are one of the most used extension points in Velox. Since Velox is a vectorized engine, by nature functions are "vector functions" that consume Velox vectors (batches of data) and produce vectors. Velox allows users to write functions as vector functions or as single-row operations "simple functions" that are converted to vector functions using template expansion through SimpleFunctionAdapter.
Writing functions as vector functions directly gives the user complete control over the function implementations and optimizations, however it comes with some cost that can be summarized in three points:
Complexity : Requires an understanding of Velox vectorized data representation and encodings, which requires additional work for our customers, specially those without DB background. Moreover, Writing optimized vector functions requires even deeper understanding.
Repetition : Involves repeated efforts and code; in each function, authors have to decode the input vectors, apply the same optimizations, and build the output vectors. For example, most arithmetic functions need benefits from a fast path when all the inputs are flat-encoded, authors need to implement that for every function that benefits from it.
Reliability : More code means more bugs, especially in such a complex context.
Writing functions through the simple interface mitigates the previously mentioned drawbacks, and significantly simplifies the function authoring process. For example, to add the function plus the user only needs to implement the PlusFunction struct shown in the graph above , which is then expanded using template expansion to a vector function.
However, the simple function interface does not give the user full control over the authoring and has its own limitations, for example the function map_keys can be implemented in O(1) as a vector function by moving the keys vector; this is not possible to express as a simple function.
Another limitation is that when using the simple interface, authors do not have access to the encodings of the input vectors, nor control over the encoding of the result vector. Hence, do not have the power to optimize the code for specific input encodings or optimize it by generating specific output encodings. The array_sort function for instance does not need to re-order the elements and copy them during sorting; instead it can generate a dictionary vector as an output, which is something not expressible as a simple function.
In the ideal world we would like to add most of the optimization that someone can do in a vector function to the simple functions adapter, so it would be enabled automatically. We have identified a number of optimizations that apply to all functions and implemented these generically in the SimpleFunctionAdapter. In this way, we can achieve the best of the two worlds and gain Simplicity, Efficiency and Reliability for most functions.
In the past year, we have been working on several improvements to the simple function interface on both the expressivity and performance axes that we will discuss in this series of notes.
In this blog post, we will talk about some of the general optimizations that we have in the adapter, the optimizations discussed in this post make the performance of most simple functions that operates on primitive types matches their counter optimized vector function implementations. In the next blog post, we will discuss complex types in simple functions.
If the output type matches one of the input types, and the input vector is to die after the function invocation, then it is possible to reuse it for the results instead of allocating a new vector. For example, in the expression plus(a, b), if a is stored in a flat vector that is not used after the invocation of the plus function, then that vevtor can be used to store the reults of the computation instead of allocating a new vevtor for the results.
Nulls are represented in a bit vector, hence, writing each bit can be expensive specially for primitive operations (like plus and minus). One optimization is
to optimize for the not null case, and bulk setting the nulls to not null. After that during the computation, only if the results are null, the null bit is set to null.
The adapter can statically infer if a function never generates null; In the simple function interface if the call function return's type is void, it means the output is never null, and if it's bool, then the function returns true for not null and false for null).
When the function does not generate nulls, then null setting is completely avoided during the computation (only the previous bulk setting is needed). The consequence of that is that the hot loop applying the function becomes simdizable triggering a huge boost in performance for primitive operations.
Worth to note also that if the simple function happens to be inlined in the adapter, then even if its return type is not void, but it always returns true then the compiler will be able to infer that setting nulls is never executed and would remove the null setting code.
Vectors in Velox can have different encodings (flat, constant..etc). The generic way of reading a vector of arbitrary encoding is to use a decoded vector to guarantee correct data access. Even though decoded vectors provide a consistent API and make it easier to handle arbitrarily encoded input data, they translate into an overhead each time an input value is accessed (we need to check the encoding of the vector to know how to read the value for every row).
When the function is a primitive operation like plus or minus, such overhead is expensive! To avoid that, encoding based fast paths can be added, the code snippet below illustrates the idea.
In the code above, the overhead of checking the encoding is switched outside the loop that applies the functions (the plus operation here). And the inner loops are simple operations that are potentially simdizable and free of encoding checks.
One issue with this optimization is that the core loop is replicated many times. In general, the numbers of times it will be replicated
is n^m where n is the number of args, and m is the number of encodings.
To avoid code size blowing, we only apply this optimization when all input arguments are primitives and the number of input arguments is <=3.
The figure below shows the effect of this optimization on the processing time of a query of primitive operations (the expression is a common pattern in ML use cases).
To compromise for both (performance and code size) when the conditions for specializing for all encodings are not met, we have a pseudo specialization mode that does not blow up the code size, but still reduce the overhead of decoding to a single multiplication per argument. This mode is enabled when all the primitive arguments are either flat or constant. The code below illustrates the idea:
When the input vector is constant we can read the value always from index 0 of the values buffer, and when it is flat we can read it from the index row; this can be achieved by assigning a factor to either 0 or 1 and reducing the decoding operation per row into a multiplication with that factor Note that such a multiplication does not prevent simd. The graph above shows that the psudeo specialization makes the program 1.6X fatser wi, while the complete specialization makes the program 2.5X faster.
Functions with string inputs can be optimized when the inputs are known to be ascii. For example the length function for ascii strings is the size of the StringView O(1). But for non-ascii inputs the computation is a more complicated O(n) operation.
Users can define a function callAscii() that will be called when all the string input arguments are ascii.
When an input string (or portion of it, reaches the output as is) it does not need to be deep copied. Instead only a StringView needs to be set. Substring is an example of a function that benefits from this. This can be done in the simple function interface in two simple steps.
Using setNoCopy(); to set the output results without copying string vectors.
Inform the function to make the output vector share ownership of input string buffers, this can be by setting the field reuse_strings_from_arg.
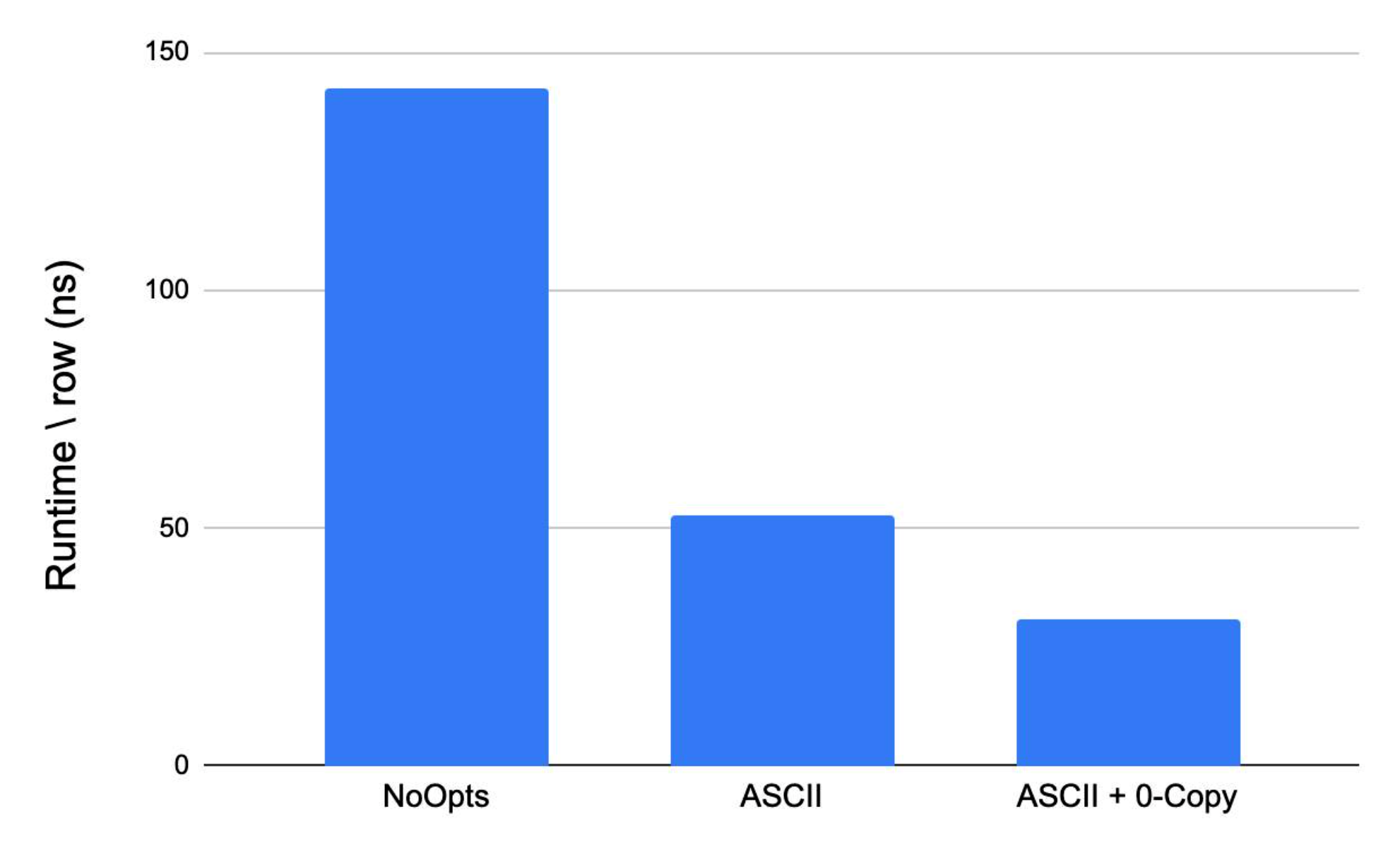
The graph below shows the effect of the previous two optimizations on the performance of the substring function.
Runtime of function substring with different optimizations.
Users can pre-process constant inputs of functions to avoid repeated computation by defining initialize function which is called once during query compilations and receives the constant inputs. For example, a regex function with constant pattern would only needs to compile the pattern expressions only once when its constant.
For more information about how to write simple functions check the documentation and the examples.
We are extremely excited to introduce Velox as an open-source project, with a mission to define common standards for modular data processing systems. Velox provides reusable, extensible, high-performance, and dialect-agnostic data processing components for building execution engines, and enhancing data management systems. We envision Velox to be the defacto execution engine for Arrow-compatible data format powering ML and Analytical workloads.
The Velox team has been partnering with companies such as Ahana, Intel, and Voltron Data as well as various academic institutions to accelerate innovation and development in the data management industry.
Looking at the future, we believe Velox’s unified and modular nature has the potential to disrupt the data management industry. It will allow us to deepen our partnership with hardware vendors and proactively adapt our unified software stack as hardware advances. We believe that modularity and reusability are the future of database system development and hope a vibrant open source community will help us in this journey.
Quick Introduction -
If you are excited to learn what’s under the hood, refer to the Velox research paper.
If you are interested in contributing, visit our Contributing guide on Github. For technical discussions and exploring what’s happening within our community, refer to the discussions section.
We will be publishing a series of technical blogs on various topics on our website soon!
For more updates and exciting news follow us on Twitter.